
From Clean Monday to Cyber Cleanliness: Bridging Traditions with Modern Cyber Hygiene Practices
By Anastasios Arampatzis and Ioannis Vassilakis
In the heart of Greek tradition lies Clean Monday, which marks the beginning of Lent leading to Easter and symbolizes a fresh start, encouraging cleanliness, renewal, and preparation for the season ahead. This day, celebrated with kite flying, outdoor activities, and cleansing the soul, carries profound significance in purifying one’s life in all aspects.
Just as Clean Monday invites us to declutter our homes and minds, there exists a parallel in the digital realm that often goes overlooked: cyber hygiene. Maintaining a clean and secure online presence is imperative in an era where our lives are intertwined with the digital world more than ever.
Understanding Cyber Hygiene
Cyber hygiene refers to the practices and steps that individuals take to maintain system health and improve online security. These practices are akin to personal hygiene routines; just as regular handwashing can prevent the spread of illness, everyday cyber hygiene practices can protect against cyber threats such as malware, phishing, and identity theft.
The importance of cyber hygiene cannot be overstated. In today’s interconnected world, a single vulnerability can lead to a cascade of negative consequences, affecting not just the individual but also organizations and even national security. The consequences of neglecting cyber hygiene can be severe:
- Data breaches.
- Identity theft.
- Loss of privacy.
As we celebrate Clean Monday and its cleansing rituals, we should also adopt cyber hygiene practices to prepare for a secure and private digital future free from cyber threats.
Clean Desk and Desktop Policies – The Foundation of Cyber Cleanliness
Just as Clean Monday encourages us to purge our homes of unnecessary clutter, a clean desk and desktop policy is the cornerstone of maintaining a secure and efficient workspace, both physically and digitally. These policies are not just about keeping a tidy desk; they’re about safeguarding sensitive information from prying eyes and ensuring that critical data isn’t lost amidst digital clutter.
- Clean Desk Policy ensures that sensitive documents, notes, and removable storage devices are secured when not in use or when an employee leaves their desk. It’s about minimizing the risk of sensitive information falling into the wrong hands, intentionally or accidentally.
- Clean Desktop Policy focuses on the digital landscape, advocating for a well-organized computer desktop. This means regularly archiving or deleting unused files, managing icons, and ensuring that sensitive information is not exposed through screen savers or unattended open documents.
The benefits of these policies are profound:
- Reduced risk of information theft.
- Increased efficiency and enhanced productivity.
- Enhanced professional image and competence.
The following simple tips can help you maintain cleanliness:
- Implement a Routine: Just as the rituals of Clean Monday are ingrained in our culture, incorporate regular clean-up routines for physical and digital workspaces.
- Secure Sensitive Information: Use locked cabinets for physical documents and password-protected folders for digital files.
- Adopt Minimalism: Keep only what you need on your desk and desktop. Archive or delete old files and dispose of unnecessary paperwork.
Navigating the Digital Landscape: Ad Blockers and Cookie Banners
Using ad blockers and understanding cookie banners are essential for maintaining a clean and secure online browsing experience. As we carefully select what to keep in our homes, we must also choose what to allow into our digital spaces.
- Ad Blockers prevent advertisements from being displayed on websites. While ads can be a source of information and revenue for site owners, they can also be intrusive, slow down web browsing, and sometimes serve as a vector for malware.
- Cookie Banners inform users about a website’s use of cookies. Understanding and managing these consents can significantly enhance your online privacy and security.
To achieve a cleaner browsing experience:
- Choose reputable ad-blocking software that balances effectiveness with respect for websites’ revenue models. Some ad blockers allow non-intrusive ads to support websites while blocking harmful content.
- Take the time to read and understand what you consent to when you agree to a website’s cookie policy. Opt for settings that minimize tracking and personal data collection where possible.
- Regularly review and clean up your browser’s permissions and stored cookies to ensure your online environment remains clutter-free and secure.
Cultivating Caution in Digital Interactions
In the same way that Clean Monday prompts us to approach our physical and spiritual activities with mindfulness and care, we must also navigate our digital interactions with caution and deliberateness. While brimming with information and connectivity, the digital world also harbors risks such as phishing scams, malware, and data breaches.
- Verify Before You Click: Ensure the authenticity of websites before entering sensitive information, and be skeptical of emails or messages from unknown sources.
- Use BCC in Emails When Appropriate: Sending emails, especially to multiple recipients, should be handled carefully to protect everyone’s privacy. Using Blind Carbon Copy (BCC) ensures that recipients’ email addresses are not exposed to everyone on the list.
- Recognize and Avoid Phishing Attempts: Phishing emails are the digital equivalent of wolves in sheep’s clothing, often masquerading as legitimate requests. Learning to recognize these attempts can protect you from giving away sensitive information to the wrong hands.
- Embrace skepticism in your online interactions: Ask yourself whether information shared is necessary, whether links are safe to click, and whether personal data needs to be disclosed.
Implementing a Personal Cyber Cleanliness Routine
Drawing inspiration from the rituals of Clean Monday, establishing a personal routine for cyber cleanliness is beneficial and essential for maintaining digital well-being. The following steps can help show a cleaner digital life.
- Enable Multi-Factor Authentication (MFA) wherever it is possible to keep unauthorized users out of personal accounts.
- Periodically review privacy settings on social media and other online platforms to ensure you only share what you intend to.
- Unsubscribe from unused services, delete old emails and remove unnecessary files to reduce the cognitive load and make it easier to focus on what’s important.
- Just as Clean Monday marks a time for physical and spiritual cleansing, set specific times throughout the year for digital clean-ups.
- Keep abreast of the latest in cybersecurity to ensure your practices are up-to-date. Knowledge is power, particularly when it comes to protecting yourself online.
- Share your knowledge and habits with friends, family, and colleagues. Just as traditions like Clean Monday are passed down, so too can habits of cyber cleanliness.
Embracing a Future of Digital Cleanliness and Renewal
The principles of Clean Monday can also be applied to our digital lives. Maintaining a healthy, secure digital environment is a continuous commitment and requires regular maintenance. We take proactive steps toward securing our personal and professional data by implementing clean desk and desktop policies, navigating the digital landscape with caution, and cultivating a routine of personal cyber cleanliness. Let us embrace this opportunity for a digital clean-up and create a safer digital world for all.

Spyware: A New Threat to Privacy in Communication
*By Sofia Despoina Feizidou
The Athens Polytechnic uprising in November 1973 was the most massive anti-dictatorial protest and a precursor to the collapse of the military dictatorship regime imposed on the Greek people since April 21, 1963. Among other things, this regime had abolished fundamental rights.
One of the most critical fundamental rights is the right to the protection of correspondence, especially the confidentiality of communication. The right of an individual to share and exchange thoughts, ideas, feelings, news, and opinions within an intimate and confidential framework, with chosen individuals, without fear of private communication being monitored or any expression being revealed to third parties or used against them, is essential to democracy. Therefore, it is a fundamental individual right enshrined in international and European legislation, as well as in national Constitutions. The provision of Article 19 of the Greek Constitution dates back to 1975 (which may not be a coincidence).
However, the revelation of the surveillance of politicians or their relatives, actors, journalists, businessmen, and others one year ago shows that the protection of communication privacy remains vulnerable, especially in the modern digital age.
Spyware: A New Asset in the Arsenal of Intelligence Services and Companies
Spyware is a type of malware designed to secretly monitor a person's activities on their electronic devices, such as computers or mobile phones, without the end user's knowledge or consent. Spyware is typically installed on devices by opening an email or a file attachment. Once installed, it is difficult to detect, and even if detected, proving responsibility for the invasion is challenging. Spyware provides full and retroactive access to the user’s device, monitoring internet activity and gathering sensitive information and personal data, including files, messages, passwords, or credit card numbers. Additionally, it can capture screenshots or monitor audio and video by activating the device's microphone or camera.
Some of the most well-known spyware designed to invade and monitor mobile devices remotely include:
- Predator: This spyware is installed on the device when a user receives a message containing a link that appears normal and includes a catchy description to mislead the user into clicking on the link. Once clicked, the spyware is automatically installed, granting full access to the device, messages, files, as well as its camera and microphone.
- Pegasus: Similar to Predator, Pegasus aims to convince the user to click on a link, which then installs the spyware on the device. However, Pegasus can also be installed on a device without requiring any action from the user, such as a missed call on WhatsApp. Immediately after installation, it executes its operator's commands and gathers a significant amount of personal data, including files, passwords, text messages, call records, or the user’s location, leaving no trace of its existence on the device.
In June 2023, the Chairman of the European Parliament’s Committee of Inquiry investigating the use of Pegasus and similar surveillance spyware stated: "Spyware can be an effective tool in fighting crime, but when used wrongly by governments, it poses a significant risk to the rule of law and fundamental rights." Indeed, the technological capabilities of spyware provide unauthorized access to personal data and the monitoring of people's activities, leading to violations of the right to communication confidentiality, the right to the protection of personal data, and the right to privacy in general.
According to the Committee's findings, the abuse of surveillance spyware is widespread in the European Union. In addition to Greece, the use of such software has been found in Poland, Hungary, Spain, and Cyprus, which is deeply concerning. The need to establish a regulatory framework to prevent such abuse is now in the spotlight, not only at the national level but primarily at the EU level.
What Do We Need?
- Clear Rules to Prevent Abuse: European rules should clearly define how law enforcement authorities can use spyware. The use of spyware by law enforcement should only be authorized in exceptional cases, for a predefined purpose, and for a limited period of time. A common legal definition of the concept of 'national security reasons' should be established. The obligation to notify targeted individuals and non-targeted individuals whose data were accessed during someone else’s surveillance, as well as procedures for supervision and independent control following any incident of illegal use of such software, should also be enshrined.
- Compliance of National Legislation with European Court of Human Rights Case Law: The Court grants national authorities wide discretion in weighing the right to privacy against national security interests. However, it has developed and interpreted the criteria introduced by the European Convention of Human Rights, which must be met for a restriction on the right to confidential, free communication to be considered legitimate. This has been established in numerous judgments since 1978.
- Establishment of the "European Union Technology Laboratory": This independent research institute would be responsible for investigating surveillance methods and providing technological support, such as device screening and forensic research.
- Foreign Policy Dimension: Members of the European Parliament (MEPs) have called for a thorough review of spyware export licenses and more effective enforcement of the EU’s export control rules. The European Union should also cooperate with the United States in developing a common strategy on spyware, as well as with non-EU countries to ensure that aid provided is not used for the purchase and use of spyware.
Conclusion
In conclusion, as we reflect upon the lessons of history and the enduring struggle for democracy and fundamental rights, Benjamin Franklin's timeless wisdom resonates with profound significance: "They who can give up essential liberty to obtain a little temporary safety, deserve neither liberty nor safety." The recent revelations of spyware abuse have starkly illustrated the delicate balance between security and individual freedoms. While spyware may be wielded as a tool in the fight against crime, its potential for misuse poses a grave threat to the rule of law and the very principles upon which our democratic societies are built.
*Sofia-Despina Feizidou is a lawyer, and graduate of the Athens Law School, holding a Master's degree with specialization in "Law & Information and Communication Technologies" from the Department of Digital Systems of the University of Piraeus. Her thesis was on the comparative review of the case law of the European Courts (ECtHR and CJEU) on mass surveillance.

The Challenge of Complying with New EU Legislative Security Requirements
By Anastasios Arampatzis and Eleftherios Chelioudakis
Over the past years, the number of digital policy initiatives at the EU level has expanded. Many legislative proposals covering Information and Communication Technologies (ICT) and influencing the rights and freedoms of people in the EU have been adopted, while others remain under negotiations. Most of these legislative acts are crucial, dealing with a wide range of complex topics, such as AI, data governance, privacy and freedom of expression online, access to digital data by law enforcement authorities, e-health, and cybersecurity.
Civil society actors often need help to follow the EU policy initiatives, while businesses face severe challenges in understanding the complex legal language of the legislative requirements. This article aims to raise awareness about two recently adopted EU legislations on cybersecurity, namely the Digital Operational Resilience Act (DORA) and the revised version of the Network and Information Security Directive (NIS2).
NIS2
NIS2 is the much-needed response to the expanding landscape threatening critical European infrastructure.
The original version of the Directive introduced several obligations for national supervision of operators of essential services (OES) and critical digital service providers (DSP). For example, EU Member states must supervise the cybersecurity level of operators in critical sectors, such as energy, transport, water, healthcare, digital infrastructure, banking, and financial market infrastructures. Moreover, Member States must supervise critical digital service providers, including online marketplaces, cloud computing services, and search engines.
For this reason, the EU Member States are to establish competent national authorities in charge of these supervisory tasks. In addition, NIS introduced channels for cross-border cooperation and information sharing between the EU Member States.
However, the digitalization of services and the increased level of cyberattacks throughout the EU led the European Commission in 2020 to propose a revised version of the NIS, namely NIS2. The new Directive entered into force on 16 January 2023, and the Member States now have 21 months, until 17 October 2024, to transpose its measures into national law.
The new Directive has broadened the scope of the NIS to strengthen the security requirements imposed in EU Member States, streamline reporting obligations, and introduce more robust supervisory measures and stricter enforcement requirements, such as harmonized sanctions regimes across EU Member States.
NIS2 introduces the following aspects:
- Expanded applicability: NIS2 increases the number of sectors covered by its provisions, including postal services, car manufacturers, social media platforms, waste management, chemical production, and agri-food. The new rules classify the entities into ‘Essential entities’ and ‘Important entities’ and apply to subcontractors and service providers operating within the covered sectors.
- Increased readiness for global cyber threats: NIS2 seeks to enhance collective situational awareness among essential entities to identify and communicate related threats before they expand across Member States. For example, the EU-CyCLONe network will assist in coordinating and managing large-scale incidents, while a voluntary peer-learning mechanism will be established to support awareness.
- Streamlined resilience standards with stricter penalties. Unlike NIS, NIS2 provides for high penalties and robust security measures. For example, infringements by essential entities shall be subject to administrative fines of a maximum of at least €10 million or 2% of their total global annual turnover, while important entities shall be fined a maximum of at least €7 million or 1.4 % of their total global annual turnover.
- Streamlined reporting processes. NIS2 streamlines the reporting obligations to avoid causing over-reporting and creating an excessive burden on the entities covered.
Expanded territorial scope: According to the new rules, specific categories of entities not established in the European Union but offering services within it will be obliged to designate a representative in the EU.
DORA
The Digital Operational Resilience Act (DORA) addresses a fundamental problem in the EU financial ecosystem: how the sector can stay resilient during severe operational disruption. Before DORA, financial institutions used capital allocation to manage the significant operational risk categories. However, they need to better address and integrate cybersecurity resilience into their larger operational frameworks in the evolving threat landscape.
The European Council press release provides a comprehensive statement of the purpose of the Digital Operational Resilience Act:
“DORA sets uniform requirements for the security of network and information systems of companies and organizations operating in the financial sector as well as critical third parties which provide ICT (Information Communication Technologies)-related services to them, such as cloud platforms or data analytics services.”
In other words, DORA creates a homogeneous regulatory framework on digital operational resilience to ensure that all financial entities can prevent and mitigate cyber threats.
Per Article 2 of the Regulation, DORA applies to financial entities, including banks, insurance companies, investment firms, and crypto-asset service providers. The Regulation also covers critical third parties offering financial companies IT and cybersecurity services.
Because DORA is a Regulation and not a Directive, it is enforceable and directly applicable in all EU Member States from its application date. DORA supplements the NIS2 directive and addresses possible overlaps as “lex specialis”.
DORA compliance is broken down into five pillars covering diverse IT and cybersecurity facets, giving financial firms a thorough foundation for digital resilience.
- ICT risk management: Internal governance and control processes ensure the effective and sensible management of ICT risk.
- ICT-related incident management, classification, and reporting: Detect, manage and alert ICT-related incidents by defining, establishing and implementing a cybersecurity incident response and management process.
- Digital operational resilience testing: Evaluate readiness for managing cybersecurity incidents, spot flaws, shortcomings, and gaps in digital operational resilience, and swiftly put corrective measures in place.
- Managing ICT third-party risk: This is an integral component of cybersecurity risk within the ICT risk management framework.
- Information sharing: Exchange cyber threat information and intelligence, including indicators of compromise, tactics, techniques, and procedures (TTP), and cybersecurity alerts, to enhance the resilience of financial entities.
According to Article 64, the Regulation entered into force on 17 January 2023 and “shall apply from 17 January 2025.” It is also important to note that Article 58 specifies that by 17 January 2026, the European Commission shall review “the appropriateness of strengthened requirements for statutory auditors and audit firms as regards digital operational resilience.”
Four steps to compliance today
Although the deadlines are further down the line, affected organizations do not have to sit and wait. Time (and money) is precious when preparing to achieve compliance with the NIS2 and DORA requirements. Organizations must assess and identify actions they can take to prepare for the new rules.
The following recommendations are a good starting point:
- Governance and risk management: Understand the new requirements and evaluate the current governance and risk management processes. Additionally, consider increasing funding for programs that help detect threats and incidents and strengthening enterprise-wide cybersecurity awareness training initiatives.
- Incident reporting: Evaluate the maturity of incident management and reporting to understand current state capabilities and gauge awareness of the various cybersecurity incident reporting standards relevant to your industry. You should also check your ability to recognize near-miss situations.
- Resilience testing: Recognize the talents needed to design and carry out resilience testing, including board member training sessions on the techniques used and their implications for repair.
- Third-party risk management: To assist in creating a risk containment plan, concentrate on enhancing contract mapping and assessing third-party vulnerabilities. Recognize the services that are essential for hosting fundamental business processes. Check to see if a fault-tolerant architecture has been implemented to lessen the impact of critical provider disruption.
This article was prepared as part of the project “Increasing Civic Engagement in the Digital Agenda — ICEDA” with the support of the European Union and South East Europe (SEE) Digital Rights Network. The content of this article in no way reflects the views of the European Union or the SEE Digital Rights Network.
Photo by FLY:D on Unsplash
Four steps to compliance today
Although the deadlines are further down the line, affected organizations do not have to sit and wait. Time (and money) is precious when preparing to achieve compliance with the NIS2 and DORA requirements. Organizations must assess and identify actions they can take to prepare for the new rules.
The following recommendations are a good starting point:
Governance and risk management: Understand the new requirements and evaluate the current governance and risk management processes. Additionally, consider increasing funding for programs that help detect threats and incidents and strengthening enterprise-wide cybersecurity awareness training initiatives.
Incident reporting: Evaluate the maturity of incident management and reporting to understand current state capabilities and gauge awareness of the various cybersecurity incident reporting standards relevant to your industry. You should also check your ability to recognize near-miss situations.
Resilience testing: Recognize the talents needed to design and carry out resilience testing, including board member training sessions on the techniques used and their implications for repair.

Raising Awareness Is Critical for Privacy and Data Protection
By Anastasios Arampatzis
Many believe cybersecurity and privacy are about emerging technologies, processes, hackers, and laws. Partially this is true. Technology is pervasive and has changed drastically how we live, work and communicate. High-profile data breaches make the news headlines more frequently than not, and businesses are fined enormous penalties for breaking security and privacy laws.
However, they must remember the most important pillar of data protection and privacy; the human element. Hymans create and use technology, and it is humans who even develop the regulations that govern a respectful and ethical use of technology. What is more, humans mostly feel the impact of data breaches. The human element is also responsible for the majority of data breaches. The Verizon Data Breach Investigations Report highlights that humans are responsible for 82% of successful data breaches.
If this percentage seems high, imagine that many security professionals argue that it is instead closer to 100%. Flawed applications, for example, are the artifact of humans. People manufacture insecure Internet of Things (IoT) devices. And it is humans that choose weak passwords or reuse passwords across multiple applications and platforms.
This is not to imply that we should accuse people of being “the weakest link” in cybersecurity and privacy. On the contrary, these thoughts underline the importance of individuals in preserving a solid security and privacy posture. This demonstrates how essential it is to create a security and privacy culture. Raising awareness about threats and best practices becomes the foundation of a safer digital future.
Data Threats Awareness
Our data is collected daily — your computer, smartphone, and almost every internet-connected device gather data. When you download a new app, create a new account, or join a new social media platform, you will often be asked to provide access to your personal information before you can even use it! This data might include your geographic location, contacts, and photos.
For these businesses, this personal information about you is of tremendous value. Companies use this data to understand their prospects better and launch targeted marketing campaigns. When used properly, the data helps companies better understand the needs of their customers. It serves as the basis for personalization, improving customer service, and creating customer value. They help to understand what works and what doesn’t. They also form the basis for automated and repeatable marketing processes that help companies evolve their operations.
In an article from May 2017, The Economist defined the data industry as the new oil industry. According to LSE Business Review, advertisements accounted for 92% of Facebook’s revenue and above 90% of Google’s revenue. This revenue is equal to approximately 60 billion $.
This is the point where things derail. Businesses store personal data indefinably. They use data to make inferences about your socioeconomic status, demographic information, and preferences. The Cambridge Analytica scandal was a great manifestation of how companies can manipulate our beliefs based on the psychographic profiles created by harvesting vast amounts of “innocent” personal data. Companies do not always use your data to your interest or according to your consent. Google, Apple, Facebook, Amazon, and Microsoft generate value by exploiting them, selling them (for example, via a data broker), or exchanging them for other data.
Besides the threats originating from the misuse of our data by legitimate businesses, there is always the danger coming from malicious actors who actively seek to spot gaps in data protection measures. The same Verizon report indicates that personal data are the target in 76% of data breach incidents. The truth is that data is valuable to criminals as well.
According to Keeper Security, criminals sell your stolen data in the dark web market, doing a profitable business. A Spotify account costs $2.75, a Netflix account up to $3.00, a driver’s license $20.00, a credit card up to $22.00, and a complete medical record $1.000! Now multiply these prices per unit by the million records compromised yearly, and you have a sense of the booming cybercrime economy.
Privacy Best Practices Awareness
If this reality is sending chills down your spine, don’t fret! You can take steps to control how your data is shared. You can’t lock down all your data — even if you stop using the internet, credit card companies and banks record your purchases. But you can take simple steps to manage it and take more control of whom you share it with.
First, it is best to understand the tradeoff between privacy and convenience. Consider what you get in return for handing over your data, even if the service is free. You can make informed decisions about sharing your data with businesses or services. Here are a few considerations:
-Is the service, app, or game worth your personal data?
-Can you control your privacy and still use the service?
-Is the data requested relevant to the app or service?
-If you last used an app several months ago, is it worth keeping it, knowing that it might be collecting and sharing your data?
You can adjust the privacy settings to your comfort level based on these considerations. Check the privacy and security settings for every app, account, or device. These should be easy to find in the Settings section and usually require a few minutes to change. Set them to your comfort level for personal information sharing; generally, it’s wise to lean on sharing less data, not more. You don’t have to adjust the privacy settings for every account at once; start with some apps, which will become a habit over time.
Another helpful habit is to clear your cookies. We’ve all clicked “accept cookies” and have yet to learn what it means. Regularly clearing cookies from your browser will remove certain information placed on your device, often for advertising purposes. However, cookies can pose a security risk, as hackers can easily hijack these files.
Finally, you can try privacy-protecting browsers. Looking after your online privacy can feel complicated, but specific internet browsers make the task easier. Many browsers depreciate third-party cookies and have strong privacy settings by default. Changing browsers is simple but can be very effective for protecting your privacy.
Data Protection Best Practices Awareness
Data privacy and data protection are closely related. Besides managing your data privacy settings, follow some simple cybersecurity tips to keep it safe. The following four steps are fundamental for creating a solid data protection posture.
-Create long (at least 12 characters) unique passwords for each account and device. Use a password manager to store all your passwords. Maintaining dozens of passwords securely is easier than ever, and you only need to remember one password.
-Turn on multifactor authentication (MFA) wherever permitted, even on apps that are about football or music. MFA can help prevent a data breach even if your password is compromised.
-Do not deactivate the automatic updates that come as a default with many software and apps. If you choose to do it manually, make sure you install these updates as soon as they are available.
-Do not click on links or attachments included in phishing messages. You can learn how to spot these emails or SMS by looking closely at the content and the sender’s address. If they promote urgency and fear or seem too good to be true, they are probably trying to trick you. Better safe than sorry.
This article was prepared as part of the project “Increasing Civic Engagement in the Digital Agenda — ICEDA” with the support of the European Union and South East Europe (SEE) Digital Rights Network. The content of this article in no way reflects the views of the European Union or the SEE Digital Rights Network.

Interview with Prof. Chris Brummer on cryptocurrencies and international regulatory cooperation
In recent years, cryptocurrencies have significantly grown in popularity, demand and accessibility. New “stablecoins” have emerged as a relatively low-risk asset category for institutional investors, whereas new “altcoins” have attracted retail investors due to their availability on popular fintech platforms.
These developments have amplified some of the risks inherent in the decentralized and immutable nature of the blockchain technology on which cryptocurrencies rely. Indicatively, sunk costs associated with volatility, loss of private keys or theft have become higher, whereas the financing of illicit activities has increasingly been channeled through cryptocurrencies.
We asked Chris Brummer, Professor of International Economic Law at Georgetown University*, to reflect on the importance of international regulation, standardization or regulatory cooperation in mitigating the above risks, and the challenges entailed in seeking to align or harmonize domestic regulatory approaches.
Prof. Brummer began by noting that the major risk of cryptocurrencies from an investment standpoint lies in their relative complexity — “what they are, how they operate, and the value proposition, if any, that any particular cryptoasset provides. Because of this complexity, they are difficult to price, and unscrupulous actors can exploit the relative ignorance of many investors”, Prof. Brummer explained.
As cryptoassets are inherently cross-border financial products, operating on digital platforms, the mitigation of the risks entailed in their increasing circulation and use requires international coordination.
“This could take place through informal guidelines and practices which, though not “harmonizing” approaches, should at least ensure that reforms are broadly moving in the same direction”, Prof. Brummer notes.
Countries have very different risk-reward appetites—which are defined largely by their own experiences
Achieving even a minimal degree of international consensus may nonetheless prove challenging given the existence of significant regulatory constraints at the domestic level. As Prof. Brummer explains, “for one, although the tech may be new, regulators operate within legacy legal systems. And national jurisdictions don’t identify crypto assets in the same way, in part because they identify just what is a “security” differently, and also define key intermediaries differently, from “exchanges” to “banks.” And these definitions can be difficult to modify — in the U.S. it’s in part the result of case law by the Supreme Court, whereas in other jurisdictions it may be defined by national (or in the case of the EU, regional) legislation. Coordination can thus be tricky, and face varying levels of practical difficulty.”
Apart from key differences in existing domestic regulatory structures, there may also be a mismatch in incentives across different jurisdictions. “Countries have very different risk-reward appetites—which are defined largely by their own experiences”, Prof. Brummer explains. “Take for example how cybersecurity concerns have evolved. Japan was one of the most crypto friendly jurisdictions in the world. Its light touch regulatory posture, began to change when its biggest exchange, Coincheck, was hacked, resulting in the theft of NEM tokens worth around $530 million. Following the hack, Japanese regulators required all the exchanges in the country to get an operating license. In contrast, other G20 countries like France have been more solicitous, and have even seen the potential for modernizing their financial systems and gaining a competitive advantage in a fast-growing industry, especially as firms reconsider London as a financial center in the wake of Brexit. Although not dismissive of the risks of crypto, France has introduced optional and mandatory licensing, reserving the latter for firms that seek to buy or sell digital assets in exchange for legal tender, or provide digital asset custody services to third parties.”
Users in different jurisdictions may face different regulatory constraints or enjoy varying degrees of regulatory protection
Another limiting factor of international coordination is the proliferation of domestic and international regulatory authorities. Prof. Brummer observes that “international standard-setters don’t always agree on crypto approaches, and neither do agencies within countries. International standard-setters and influencers themselves have until recently espoused very different opinions, with the Basel Committee less impressed, and the IMF—committed to payments for financial stability, more intrigued. And even within jurisdictions, regulatory bodies can take varying views. In the US, for example, the SEC has at least been seen to be far more wary of crypto than the CFTC; similarly, from an outsider’s perspective, the ECB’s stance has appeared to be more cautious than, say ESMA’s.”
For the time being, international regulatory cooperation appears to be evolving slowly, in light of the limitations listed above by Prof. Brummer. Users in different jurisdictions, even within the EU, may therefore face different regulatory constraints or enjoy varying degrees of regulatory protection. The Bank of Greece, for one, has issued announcements adopting the views of European supervisory authorities warning consumers of the risks of cryptocurrencies, but has yet to adopt precise guidelines. Yet, as stablecoin projects popularized by established commercial actors gain popularity, we may soon begin to see a shift in international regulatory pace, possibly toward a greater degree of convergence.
* Chris Brummer is the host of the popular Fintech Beat podcast, and serves as both a Professor of Law at Georgetown and the Faculty Director of Georgetown’s Institute of International Economic Law. He lectures widely on fintech, finance and global governance, as well as on public and private international law, market microstructure and international trade. In this capacity, he routinely provides analysis for multilateral institutions and participates in global regulatory forums, and he periodically testifies before US and EU legislative bodies. He recently concluded a three-year term as a member of the National Adjudicatory Council of FINRA, an organization empowered by the US Congress to regulate the securities industry.
** Photo Credits: Jinitzail Hernández / CQ Roll Call

Digital Cartels: The Risks, the Role of Big Data, the Possible Measures & the Role of the EU
By Konstantinos Kaouras*
The risks of tacit collusion have increased in the 21st century with the use of algorithms and machine learning technologies.
In the literature, the term “collusion” commonly refers to any form of co-ordination or agreement among competing firms with the objective of raising profits to a higher level than the non-cooperative equilibrium, resulting in a deadweight loss.
Collusion can be achieved either through explicit agreements, whether they are written or oral, or without the need for an explicit agreement, but with the recognition of the competitors’ mutual interdependence. In this article, we will deal with the second form of collusion which is referred to as “tacit collusion”.
The phenomenon of “tacit collusion” may particularly arise in oligopolistic markets where competitors, due to their small number, are able to coordinate on prices. However, the development of algorithms and machine learning technologies has made it possible for firms to collude even in non-oligopolistic markets, as we will see below.
Tacit Collusion & Pricing Algorithms
Most of us have come across pricing algorithms when looking to book airline tickets or hotel rooms through price comparison websites. Pricing algorithms are commonly understood as the computational codes run by sellers to automatically set prices to maximise profits.
But what if pricing algorithms were able to set prices by coordinating with each other and without the need for any human intervention? As much as this sounds like a science fiction scenario, it is a real phenomenon observed in digital markets, which has been studied by economists and has been termed “algorithmic (tacit) collusion”.
Algorithmic tacit collusion can be achieved in various ways as follows:
- Algorithms have the capability “to identify any market threats very fast, for instance through a phenomenon known as now-casting, allowing incumbents to pre-emptively acquire any potential competitors or to react aggressively to market entry”.
- They increase market transparency and the frequency of interaction, making the industries more prone to collusion.
- Algorithms can act as facilitators of collusion by monitoring competitors’ actions in order to enforce a collusive agreement, enabling a quick identification of ‘cartel price’ deviations and retaliation strategies.
- Co-ordination can be achieved in a sort of “hub and spoke” scenario where competitors may use the same IT companies and programmers for developing their pricing algorithms and end up relying on the same algorithms to develop their pricing strategies. Similarly, a collusive outcome could be achieved if most companies were using pricing algorithms to follow in real-time a market leader (tit-for-tat strategy), who in turn would be responsible for programming the dynamic pricing algorithm that fixes prices above competitive level.
- “Signaling algorithms” may enable companies to automatically set very fast iterative actions, such as snapshot price changes during the middle of the night, that cannot be exploited by consumers, but which can still be read by rivals possessing good analytical algorithms.
- “Self-learning algorithms” may eliminate the need for human intermediation, as using deep machine learning technologies, the algorithms may assist firms in actually reaching a collusive outcome without them being aware of it.
Algorithms & Big Data: Could they Decrease the Risks of Collusion?
Big Data is defined as “the information asset characterized by such a high volume, velocity and variety to require specific technology and analytical methods for its transformation into value”.
It can be argued that algorithms which constitute a “well defined computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as outputs” can provide the necessary technology and analytical methods to transform raw data into Big Data.
In data-driven ecosystems, consumers can outsource purchasing decisions to algorithms which act as their “digital half” and/or they can aggregate in buying platforms, thus, strengthening their buyer power.
Buyers with strong buying power can disrupt any attempt to reach terms of coordination, thus making tacit collusion an unlikely outcome. In addition, algorithms could recognise forms of co-ordination between suppliers (i.e. potentially identifying instances of collusive pricing) and diversify purchasing proportions to strengthen incentives for entry (i.e. help sponsoring new entrants).
Besides pure demand-side efficiencies, “algorithmic consumers” also have an effect on suppliers’ incentives to compete as, with the help of pricing algorithms, consumers are able to compare a larger number of offers and switch suppliers.
Furthermore, the increasing availability of online data resulting from the use of algorithms may provide useful market information to potential entrants and improve certainty, which could reduce entry costs.
If barriers to entry are reduced, then collusion can hardly be sustained over time. In addition, algorithms can naturally be an important source of innovation, allowing companies to develop non-traditional business models and extract more information from data, and, thus, lead to the reduction of the present value of collusive agreements.
Measures against Digital Cartels and the Role of the EU
Acknowledging that any measures against algorithmic collusion may have possible effects on competition, competition authorities may adopt milder or more radical measures depending on the severity and/or likelihood of the risk for collusion.
To begin with, they may adopt a wait-and-see approach conducting market studies and collecting evidence about the real occurrence of algorithmic pricing and the risks for collusion.
Where the risk for collusion is medium, they could possibly amend their merger control regime lowering their threshold of intervention and investigating the risk of coordinated effects in 4 to 3 or even 5 to 4 mergers.
In addition, they could regulate pricing algorithms ex ante with some form of notification requirement and prior analysis, eventually using the procedure of regulatory sandbox.
Such prior analysis could be entrusted to a “Digital Clearing House”, a voluntary network of contact points in regulatory authorities at national and EU level who are responsible for regulation of the digital sector, and should be able to analyze the impact of pricing algorithms on the digital rights of users.
At the same time, competition authorities could adopt more radical legislative measures by abandoning the classic communications-based approach for a more “market-based” approach.
In this context, they could redefine the notion of “agreement” in order to incorporate other “meetings of minds” that are reached with the assistance of algorithms. Similarly, they could attribute antitrust liability to individuals who benefit from the algorithms’ autonomous decisions.
Finally, where the risk for collusion is serious, competition authorities could either prohibit algorithmic pricing or introduce regulations to prevent it, by setting maximum prices, making market conditions more unstable and/or creating rules on how algorithms are designed.
However, given the possible effects on competition, these measures should be carefully considered.
Given most online companies using pricing algorithms operate beyond national borders and the EU has the power to externalize its laws beyond its borders (a phenomenon known as “the Brussels effect”), we would suggest that any measures are taken at EU-wide level with the cooperation of regulatory authorities who are responsible for regulation of the digital sector.
Harmonised rules at EU Regulation level such as the recently adopted General Data Protection Regulation are important to protect the legitimate interests of consumers and facilitate growth and rapid scaling up of innovative platforms using pricing algorithms.
It is worth noting that, following a proposal of the European Parliament, the European Commission is currently carrying out an in-depth analysis of the challenges and opportunities in algorithmic decision-making, while in April 2019, the High-Level Expert Group on Artificial Intelligence (AI), set up by the European Commission, presented Ethics Guidelines for Trustworthy AI, in which it was stressed that AI should foster individual users’ fundamental rights and operate in accordance with the principles of transparency and accountability.
In conclusion, given the potential benefits of algorithms, but also the risks posed by the creation of “digital cartels”, it is clear that a fine balance must be struck between adopting a laissez-faire approach, which can be detrimental for consumers, and an extremely interventionist approach, which can be harmful for competition.
* Konstantinos Kaouras is a Greek qualified lawyer who works as a Data Protection Lawyer at the UK’s largest healthcare charity, Nuffield Health. He is currently pursuing an LLM in Competition and Intellectual Property Law at UCL. He has carried out research on the interplay between Competition and Data Protection Law, while he has a special interest in the role of algorithms and Big Data.
Bibliography
Lianos I, Korah V, with Siciliani P, Competition Law Analysis, Cases, & Materials (OUP 2019)
OECD, ‘Algorithms and Collusion: Competition Policy in the Digital Age’ (2017)
OECD, ‘Big Data: Bringing Competition Policy to the Digital Era – Background Note by the Secretariat’ (2016)

Online Shopping: Do we all pay the same price for the same product?
Written by Eirini Volikou*
On the same day, three people enter a book store looking to buy the book The secrets of the Internet. The book retails for €20 but the price is not indicated. The bookseller charges the first customer to walk in – a well-dressed man holding a leather briefcase and the new iPhone – €25 for the book. A while later a regular customer arrives. The bookseller knows that he is a student with poor finances and sells the book to him for €15. Finally, the third customer shows up; a woman who seems to be in a hurry to make the purchase. She ends up purchasing The secrets of the Internet at the price of €23. None of the customers is aware that each one paid a different price because the bookseller used information he deduced from their “profiles” to deduce their buying power or willingness.
In our capacity as consumers, how would we describe such a practice?
Is it fair or unfair, correct or wrong, lawful or unlawful?
And how would we react were we made aware that it targets us as well?
The above scenario may be completely fictitious but could it materialize in the real world?
In principle, the conditions in “regular” commerce are not such as to allow the materialization of our scenario. The obligation to clearly indicate the prices of products in brick and mortar stores directly and dramatically limits the traders’ freedom in charging prices higher than those indicated based on each individual client. In e-commerce, though, reality can prove to be strikingly similar to our fictitious scenario.
The e-commerce reality aka the “bookseller” is alive
Not infrequently it is observed that the indicated price of a good or a service on e-commerce platforms is not the same for everyone but divergences occur depending on the profile of the future customer.
Our online profiles are composed of information such as gender, age, marital status, type and number of devices we use to connect to the internet, geographical location (country or even neighborhood), nationality, preferences and consumer habits (history of searches or purchases) and so on.
This information is made known to the websites we visit via cookies, our IP address, and our user log-in information and can be used not only to show results and advertisements relevant to us but also to draw conclusions about our purchasing power or willingness. In other words, the role of the fictitious bookseller play algorithms that use our profiles for the purpose of categorizing us and automatically calculating and presenting to us a final price that we would be prepared to pay for the subject of our search.
This price may differ between users or categories of users who are often unaware of such categorisation or of the price they would be asked to pay had the platform had no access to their personal data.
This practice is often referred to as personalised pricing or price discrimination.
It is not to be confused with dynamic pricing in which the price is adjusted based on criteria that are not relevant to any individual customer but based on criteria relevant to the market, such as supply and demand.
The issue of personalized pricing surfaced in the public debate in the early 2000s when regular Amazon users noticed that by deleting or blocking the relevant cookies from their devices – which meant being regarded as new users by the platform – they could purchase DVDs at lower prices. The widespread use of e-commerce in combination with the rampant collection and processing of our personal data online (profiling, data scraping, Big Data) has since paved the way for the facilitation and spread of personalized pricing.
The experiment aka the “bookseller” in action
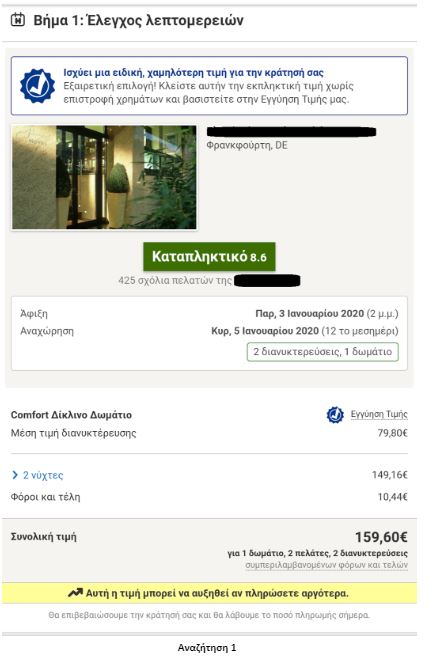
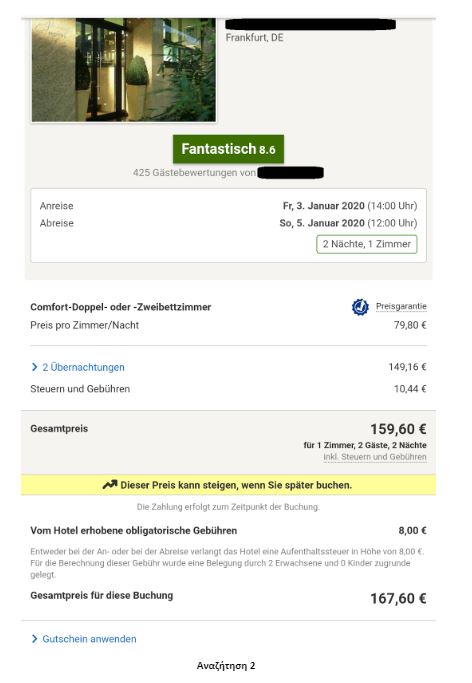
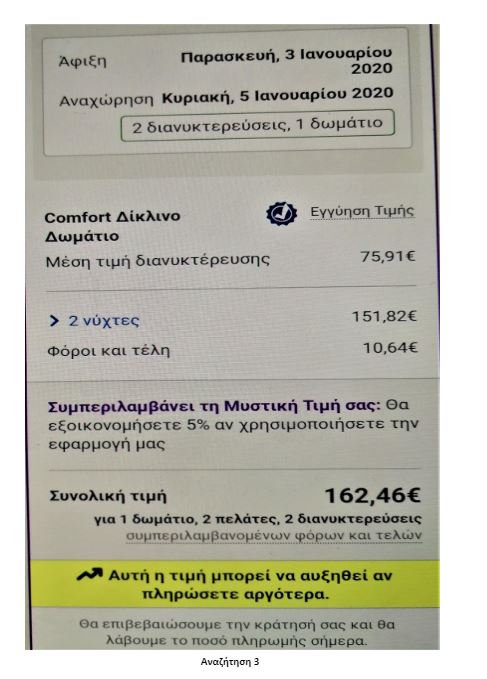
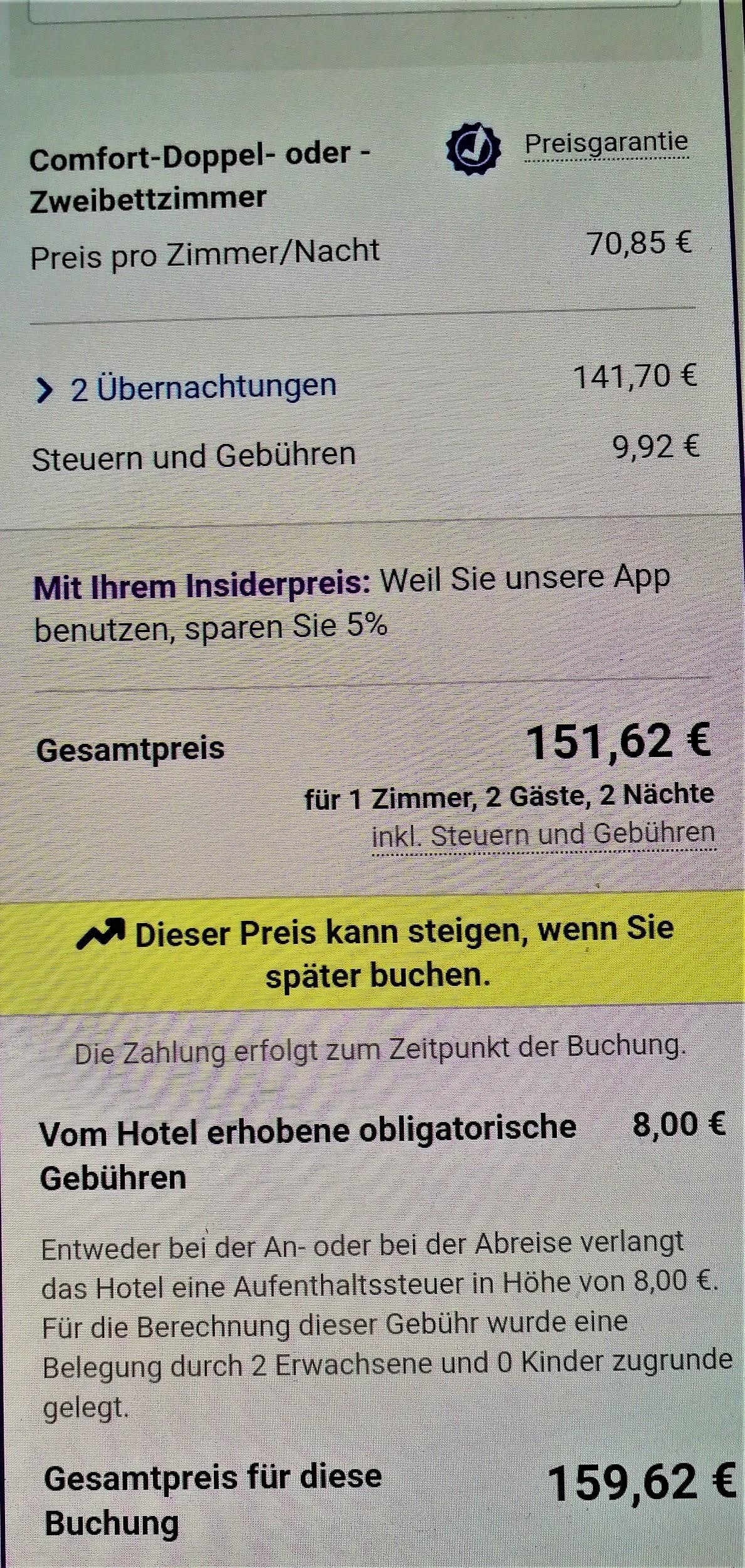
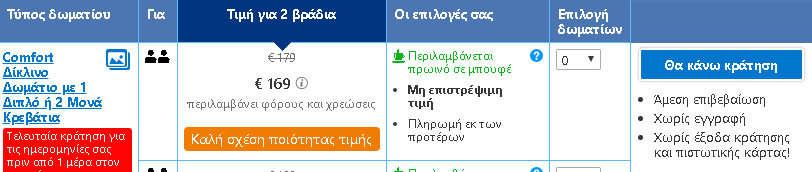
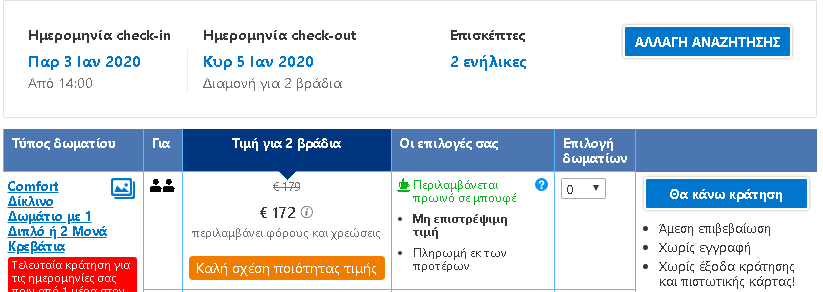
To put the practice to the test, consecutive searches and price comparisons were conducted on the same day (17/12/2019) for exactly the same room type (a “comfort” double room with one double or two twin beds) with breakfast for 2 travelers at the same hotel in Frankfurt, Germany on 3-5 January 2020. The searches were conducted on two different hotel booking websites and in all instances they reflect the lowest, non-refundable price option. The results are shown below:
Website Α
| Device | Browsing method | Website version | Price in € | |
| 1 | Τablet | Browser | Greek | 159,60 |
| 2 | Tablet | Browser | German | 167,60 |
| 3 | Tablet | Application | Greek | 162,46 |
| 4 | Tablet | Application | German | 159,62 |
Website Β
| Device | Browsing method | Website version | Price in € | |
| 5 | Laptop | Browser | Greek | 169,00 |
| 6 | Laptop | Incognito browser | Greek | 172,00 |
| 7 | Smartphone | Browser | Greek | 179,00 |
Search 1
Search 2
Search 3
Search 4
Search 5
Search 6
Search 7
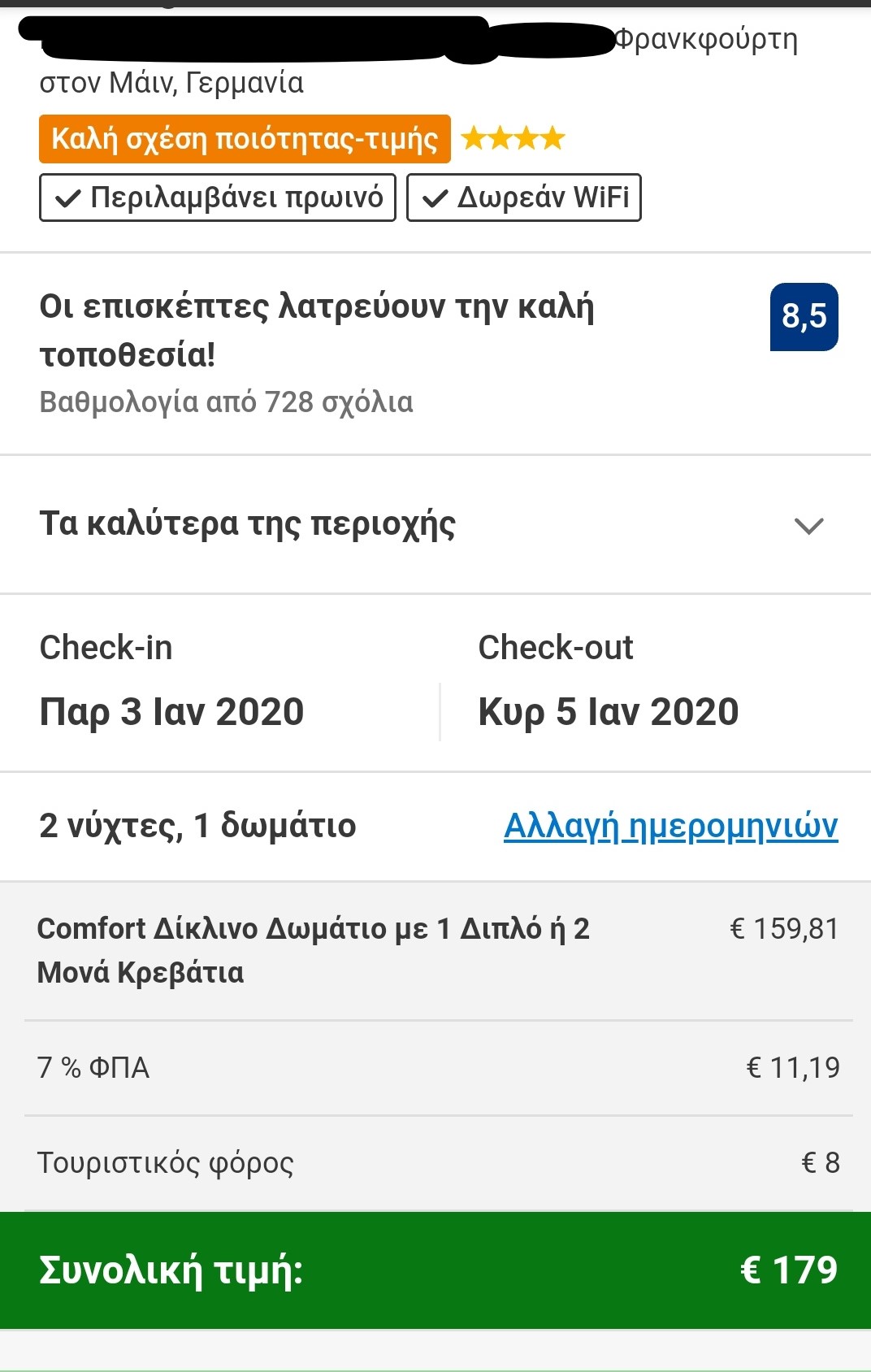
The search results show a range of different prices for the same room on the same dates.
There is a noteworthy price divergence depending on the consumer’s country or location. Even for the same country, though, the prices differ considerably depending on the type of device combined with the browsing method used.
All this information – or even the lack thereof in the case of incognito browsing – appears to play a role in the final price calculation and, hence, in the customized pricing for the users.
How is personalized pricing dealt with?
Personalised pricing, arguably, brings advantages especially for consumers with low purchasing power who benefit from lower prices or discounts and can have access to products or services that they could otherwise not afford. However, consumer categorization and price differentiation give rise to concerns because they are processes mostly unknown to consumers and obscure as to the specific criteria they employ.
At the same time, the use of parameters like the ones that appeared to influence the price in the hotel room experiment, i.e. country/language, device, and browsing method, does not guarantee a classification of purchasing power that corresponds to reality. What is more, research has shown that consumers, when made aware of the application of personalized pricing, reject this practice by a majority as unfair or unacceptable. This is largely true also in the event that personalized pricing would benefit them if they were also made aware that such benefit requires the collection of their data and the monitoring of their online or offline behavior.
When it comes to the legal approach to personalised pricing, different fields of law are concerned by it.
In the framework of data protection law, the General Data Protection Regulation (GDPR) does not explicitly regulate personalized pricing. Nevertheless, it provides that should an undertaking be using personal data (including IP address, location, the cookies stored in a device, etc.) it is obliged to inform about the purposes for which they are being used.
It follows that, if consumer profiles are being used for the calculation of the final price of a good or service, this should, at the very least, be mentioned in the privacy policy of the e-commerce platform.
The GDPR also requires consumer consent if personalized pricing has been based on sensitive personal data or if personal data is used in automated decision-making concerning the consumer.
From a consumer protection law perspective, traders can, in principle, set the prices for their goods or services freely insofar as they duly inform consumers about these prices or the manner in which they have been calculated. Personalized pricing could be prohibited if applied in combination with unfair commercial practices provided for in the text of the relevant Directive 2005/29/EC.
However, recently adopted Directive (EU) 2019/2161, which aims to achieve the better enforcement and modernization of Union consumer protection rules, will hopefully contribute to limiting consumer uncertainty and improving their position.
With the amendments that this Directive brings about not only is personalized pricing recognized as a practice but also the obligation is established to inform consumers when the price to be paid has been personalized on the basis of automated decision-making so they can take the potential risks into consideration in their purchasing decision (Recital 45 and Article 4(4) of the Directive). The Directive was published in the Official Journal of the EU on 18/12/2019 and the Member States should apply the measures transposing it by 28/5/2022.
It should be noted, albeit, in brief, that personalized pricing is an issue that competition law is also concerned with and, in particular, the possibility of charging higher prices to specific consumer categories for reasons not related to costs or for utilities by firms that hold a dominant position in a market.
In any case, staying protected online is also a personal matter.
At the Roadmap to Safe Navigation (in Greek) issued by Homo Digitalis, there can be found the behaviors we can adopt to protect our personal data while navigating through the Internet.
Consumers can adopt behaviors that help protect their personal data while browsing, such as using a virtual private network (VPN), opting for browsers and search engines that do not track users and using email and chat services that offer end-to-end encryption. To deal with personalized pricing, in particular, thorough market research, price comparison on different websites, or even different language versions of a single website, trying different browsing methods and, if possible, different devices can be a good start. It is important for e-commerce users to stay informed and alert in order to avoid having their profile used as a tool towards charging higher prices.
*Eirini Volikou, LL.M is a lawyer specializing in European and European Competition Law. She has extensive experience in the legal training of professionals on Competition Law, having worked as Deputy Head of the Business Law Section at the Academy of European Law (ERA) in Germany and, currently, as Course Co-ordinator with Jurisnova Association of the NOVA Law School in Lisbon.
SOURCES
1) European Commission – Consumer market study on online market segmentation through personalized pricing/offers in the European Union (2018)
2) Directive (EU) 2019/2161 of the European Parliament and of the Council of 27 November 2019 amending Council Directive 93/13/EEC and Directives 98/6/EC, 2005/29/EC and 2011/83/EU of the European Parliament and of the Council as regards the better enforcement and modernisation of Union consumer protection rules
3) Directive 2005/29/EC of the European Parliament and of the Council of 11 May 2005 concerning unfair business-to-consumer commercial practices in the internal market and amending Council Directive 84/450/EEC, Directives 97/7/EC, 98/27/EC and 2002/65/EC of the European Parliament and of the Council and Regulation (EC) No 2006/2004 of the European Parliament and of the Council (‘Unfair Commercial Practices Directive’)
4) Commission Staff Working Document – Guidance on the implementation/application of Directive 2005/29/EC on unfair commercial practices [SWD(2016) 163 final]
5) Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
6) Poort, J. & Zuiderveen Borgesius, F. J. (2019). Does everyone have a price? Understanding people’s attitude towards online and offline price discrimination. Internet Policy Review, 8(1)
7) OECD, ‘Personalised Pricing in the Digital Era’, Background Note by the Secretariat for the joint meeting between the OECD Competition Committee and the Committee on Consumer Policy on 28 November 2018 [DAF/COMP(2018)13]
8) BEUC, ‘Personalised Pricing in the Digital Era’, Note for the joint meeting between the OECD Competition Committee and the Committee on Consumer Policy on 28 November 2018 [DAF/COMP/WD(2018)129]9) http://news.bbc.co.uk/2/hi/business/914691.stm

Homomorphic Encryption: What is and Known Applications
Written by Anastasios Arampatzis
Every day, organizations handle a lot of sensitive information, such as personal identifiable information (PII) and financial data, that needs to be encrypted both when it is stored (data at rest) and when it is being transmitted (data in transit). Although modern encryption algorithms are virtually unbreakable, at least until the coming of quantum computing, because they require too much processing power too break them that makes the whole process too costly and time-consuming to be feasible, it is also impossible to process the data without first decrypting it. And decrypting data, makes it vulnerable to hackers.
The problem with encrypting data is that sooner or later, you have to decrypt it. You can keep your cloud files cryptographically scrambled using a secret key, but as soon as you want to actually do something with those files, anything from editing a word document or querying a database of financial data, you have to unlock the data and leave it vulnerable. Homomorphic encryption, an advancement in the science of cryptography, could change that.
What is Homomorphic Encryption?
The purpose of homomorphic encryption is to allow computation on encrypted data. Thus data can remain confidential while it is processed, enabling useful tasks to be accomplished with data residing in untrusted environments. In a world of distributed computation and heterogeneous networking this is a hugely valuable capability.
A homomorphic cryptosystem is like other forms of public encryption in that it uses a public key to encrypt data and allows only the individual with the matching private key to access its unencrypted data. However, what sets it apart from other forms of encryption is that it uses an algebraic system to allow you or others to perform a variety of computations (or operations) on the encrypted data.
In mathematics, homomorphic describes the transformation of one data set into another while preserving relationships between elements in both sets. The term is derived from the Greek words for “same structure.” Because the data in a homomorphic encryption scheme retains the same structure, identical mathematical operations, whether they are performed on encrypted or decrypted data, will result in equivalent results.
Finding a general method for computing on encrypted datahad been a goal in cryptography since it was proposed in 1978 by Rivest, Adleman and Dertouzos. Interest in this topic is due to its numerous applications in the real world. The development of fully homomorphic encryption is a revolutionary advance, greatly extending the scope of the computations which can be applied to process encrypted data homomorphically. Since Craig Gentry published his idea in 2009, there has been huge interest in the area, with regard to improving the schemes, implementing them and applying them.
Types of Homomorphic Encryption
There are three types of homomorphic encryption. The primary difference between them is related to the types and frequency of mathematical operations that can be performed on the ciphertext. The three types of homomorphic encryption are:
- Partially Homomorphic Encryption
- Somewhat Homomorphic Encryption
- Fully Homomorphic Encryption
Partially homomorphic encryption (PHE) allows only select mathematical functions to be performed on encrypted values. This means that only one operation, either addition or multiplication, can be performed an unlimited number of times on the ciphertext. Partially homomorphic encryption with multiplicative operations is the foundation for RSA encryption, which is commonly used in establishing secure connections through SSL/TLS.
A somewhat homomorphic encryption (SHE) scheme is one that supports select operation (either addition or multiplication) up to a certain complexity, but these operations can only be performed a set number of times.
Fully Homomorphic Encryption
Fully homomorphic encryption (FHE), while still in the development stage, has a lot of potential for making functionality consistent with privacy by helping to keep information secure and accessible at the same time. It was developed from the somewhat homomorphic encryption scheme, FHE is capable of using both addition and multiplication, any number of times and makes secure multi-party computation more efficient. Unlike other forms of homomorphic encryption, it can handle arbitrary computations on your ciphertexts.
The goal behind fully homomorphic encryption is to allow anyone to use encrypted data to perform useful operations without access to the encryption key. In particular, this concept has applications for improving cloud computing security. If you want to store encrypted, sensitive data in the cloud but don’t want to run the risk of a hacker breaking in your cloud account, it provides you with a way to pull, search, and manipulate your data without having to allow the cloud provider access to your data.
Applications of Fully Homomorphic Encryption
Craig Gentry mentioned in his graduation thesis that “Fully homomorphic encryption has numerous applications. For example, it enables private queries to a search engine – the user submits an encrypted query and the search engine computes a succinct encrypted answer without ever looking at the query in the clear. It also enables searching on encrypted data – a user stores encrypted files on a remote file server and can later have the server retrieve only files that (when decrypted) satisfy some boolean constraint, even though the server cannot decrypt the files on its own. More broadly, fully homomorphic encryption improves the efficiency of secure multi party computation.”
Researchers have already identified several practical applications of FHE, some of which are discussed herein:
- Securing Data Stored in the Cloud. Using homomorphic encryption, you can secure the data that you store in the cloud while also retaining the ability to calculate and search ciphered information that you can later decrypt without compromising the integrity of the data as a whole.
- Enabling Data Analytics in Regulated Industries. Homomorphic encryption allows data to be encrypted and outsourced to commercial cloud environments for research and data-sharing purposes while protecting user or patient data privacy. It can be used for businesses and organizations across a variety of industries including financial services, retail, information technology, and healthcare to allow people to use data without seeing its unencrypted values. Examples include predictive analysis of medical data without putting data privacy at risk, preserving customer privacy in personalized advertising, financial privacy for functions like stock price prediction algorithms, and forensic image recognition.
- Improving Election Security and Transparency. Researchers are working on how to use homomorphic encryption to make democratic elections more secure and transparent. For example, the Paillier encryption scheme, which uses addition operations, would be best suited for voting-related applications because it allows users to add up various values in an unbiased way while keeping their values private. This technology could not only protect data from manipulation, it could allow it to be independently verified by authorized third parties
Limitations of Fully Homomorphic Encryption
There are currently two known limitations of FHE. The first limitation is support for multiple users. Suppose there are many users of the same system (which relies on an internal database that is used in computations), and who wish to protect their personal data from the provider. One solution would be for the provider to have a separate database for every user, encrypted under that user’s public key. If this database is very large and there are many users, this would quickly become infeasible.
Next, there are limitations for applications that involve running very large and complex algorithms homomorphically. All fully homomorphic encryption schemes today have a large computational overhead, which describes the ratio of computation time in the encrypted version versus computation time in the clear. Although polynomial in size, this overhead tends to be a rather large polynomial, which increases runtimes substantially and makes homomorphic computation of complex functions impractical.
Implementations of Fully Homomorphic Encryption
Some of the world’s largest technology companies have initiated programs to advance homomorphic encryption to make it more universally available and user-friendly.
Microsoft, for instance, has created SEAL (Simple Encrypted Arithmetic Library), a set of encryption libraries that allow computations to be performed directly on encrypted data. Powered by open-source homomorphic encryption technology, Microsoft’s SEAL team is partnering with companies like IXUP to build end-to-end encrypted data storage and computation services. Companies can use SEAL to create platforms to perform data analytics on information while it’s still encrypted, and the owners of the data never have to share their encryption key with anyone else. The goal, Microsoft says, is to “put our library in the hands of every developer, so we can work together for more secure, private, and trustworthy computing.”
Google also announced its backing for homomorphic encryption by unveiling its open-source cryptographic tool, Private Join and Compute. Google’s tool is focused on analyzing data in its encrypted form, with only the insights derived from the analysis visible, and not the underlying data itself.
Finally, with the goal of making homomorphic encryption widespread, IBM released its first version of its HElib C++ library in 2016, but it reportedly “ran 100 trillion times slower than plaintext operations.” Since that time, IBM has continued working to combat this issue and have come up with a version that is 75 times faster, but it is still lagging behind plaintext operations.
Conclusion
In an era when the focus on privacy is increased, mostly because of regulations such as GDPR, the concept of homomorphic encryption is one with a lot of promise for real-world applications across a variety of industries. The opportunities arising from homomorphic encryption are almost endless. And perhaps one of the most exciting aspects is how it combines the need to protect privacy with the need to provide more detailed analysis. Homomorphic encryption has transformed an Achilles heel into a gift from the gods.
This article was originally published on the Venafi blog at: https://www.venafi.com/blog/homomorphic-encryption-what-it-and-how-it-used.

Reparations for immaterial damage under the GDPR: A new context
Written by Giorgos Arsenis*
A court in Austria sentenced a company to 800 Euros of compensation-payment towards a data-subject, for reasons of immaterial (emotional) harm, according to article 82 of the GDPR (General Data Protection Regulation). The verdict is not in force yet, since both parties have appealed the decision, but in case the verdict will remain unchanged in the second instance, then the company might be facing a mass lawsuit, where about 2 million data-subjects are involved.
The case has gained momentum since its outcome will constitute a legal paradigm, upon which future cases will be based. But let’s take a step back and have a broader look at this verdict and the consequences this application of article 82 might have towards the justice systems of other members of the European Union.
Profiling
The fact that a Post Office gathers and saves personal data of its customers is nothing new. But after a data-subject’s request, it was revealed that Austria’s Post, allegedly, evaluated and stored data that concerned the political preferences of approximately 2 million of its clients.
The said company used statistical methods such as profiling, aiming to estimate the level of affinity of a person towards an Austrian political party (e.g. significant possibility of affinity for party A, insignificant possibility of affinity for party B). According to media, it appears that none of the customers had provided their consent for this processing activity and in certain cases that information was acquired by further entities.
Immaterial harm has a price
The local court of Feldkirch in Voralberg, a confederate state of Austria bordering with Lichtenstein, where the hearing took place in the first instance, ruled that the sheer feeling of distress sensed by the claimant due to the profiling he was subjected to without his consent, constitutes immaterial harm. Therefore, the accuser was awarded 800 Euros, from the 2.500 Euros he claimed initially.
The court acknowledged that the political beliefs of a person are a special category of personal data, according to article 9 of GDPR. However, it also acknowledged that every situation perceived as unfavorable treatment, cannot give rise for compensation claims based on moral damages. Nevertheless, the court concluded that in this case, fundamental rights of the data-subject had been violated.
The calculation of the compensation was based on a method that applies in Austria. In line with that method, the court took two main elements into account: (1) that political opinions are an especially sensitive category of personal data and (2) that the processing activity was conducted without the awareness of the data-subject.
And now?
The verdict is no surprise. Article 82 § 1 of the GDPR clearly foresees compensation payment for immaterial harm. However, with 2,2 million data-subjects affected from this processing activity and simply by doing the math, what derives is the amount of 1,7 billion Euros. Certain is, that if the court of appeal confirms the decision, there will be a plethora of similar cases for litigation. This is the reason why already, in neighbouring Germany, many companies specialize in cases like this.
The Independent Authority
After the decision of the local court in Feldkirch in the beginning of October 2019, towards the end of the same month (29.10.2019) the Austrian Data Protection Authority (Österreichische Datenschutzbehörde), announced that an administrative sanction of 18 million Euros was imposed to the Austrian Postal Service. Beyond political beliefs, the independent authority detected more violations. Via further processing, evidence about the frequency of package deliveries or residence change were obtained, which were used as means for direct-marketing advertisement. The Austrian Postal Service, which by half belongs to the state, reported that it will take legal action against this administrative measure and justified the purpose of the processing activities as legitimate market analysis.
What makes the verdict distinctive
The verdict in Feldkirch shows that the courts are able to impose fines for certain “adversities” caused by real or hypothetical violations of personal data.
Unlike the independent authority, that imposed the administrative sanction due to multiple violations of the GDPR-clauses, the local court in Feldkirch focused on the ‘disturbance’ sensed by the complainant.
The complainant simply stated that he ‘felt disturbed’ for what happened, i.e. without pleading a moral damage resulting from the processing activity, such as defamation, copyright abuse or harassment by phone calls or emails. The moral damage was induced by the fact that a company is processing personal data in an unlawful manner.
You can find the decision here.
* Giorgos Arsenis is an IT Consultant και DPO. He has long-standing experience in IT Systems Implementation & Maintenance, in a number of countries in Europe. He has been active for agencies and institutions of the EU and in the private sector. He is qualified in servers, networks, scientific modelling and virtual machine environments. Freelancer, specializes on Information Security Management Systems and Personal Data Protection.
Digital Sources: